hadoop 生态系统,构建大数据处理平台的关键组件
时间:2024-10-15 来源:网络 人气:
深入解析Hadoop生态系统:构建大数据处理平台的关键组件

随着大数据时代的到来,如何高效处理和分析海量数据成为了企业关注的焦点。Hadoop生态系统作为一个开源的分布式计算框架,为处理大规模数据集提供了强大的解决方案。本文将深入解析Hadoop生态系统的关键组件,帮助读者全面了解其架构和功能。
一、Hadoop简介
Hadoop是由Apache软件基金会开发的开源分布式计算框架,主要用于处理大规模数据集。它由多个组件构成,包括HDFS、MapReduce、YARN等,共同协作以实现高效的数据存储、处理和分析。
二、Hadoop生态系统核心组件
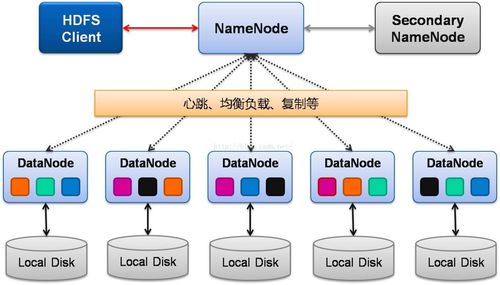
1. Hadoop分布式文件系统(HDFS)
HDFS是一个分布式文件系统,用于存储海量数据。它将数据分割成多个块,并存储在集群中的不同节点上,以确保数据的可靠性和容错性。HDFS支持高吞吐量的数据访问,适用于大规模数据存储。
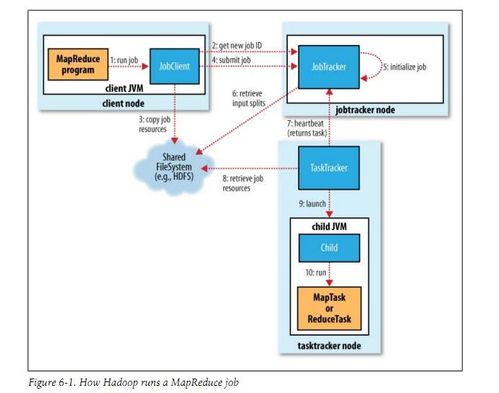
2. MapReduce
MapReduce是一个计算模型,用于并行处理大规模数据集。它将数据处理任务分解为Map和Reduce两个阶段,Map阶段将输入数据转换为键值对,Reduce阶段将键值对合并为最终结果。MapReduce适用于批处理任务,具有高效率和可扩展性。
3. YARN(Yet Another Resource Negotiator)
YARN是一个资源管理和调度框架,负责管理集群中的资源分配和任务调度。它将资源管理从MapReduce中分离出来,使得Hadoop生态系统可以支持更多类型的计算框架,如Spark、Flink等。
三、Hadoop生态系统其他重要组件
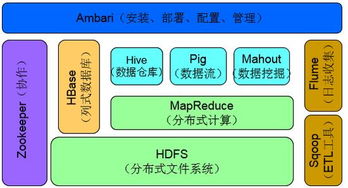
1. Hive
Hive是一个基于Hadoop的数据仓库工具,用于处理大规模数据集。它提供了一种类似SQL的查询语言,使得用户可以轻松地对存储在HDFS中的数据进行查询和分析。
2. Pig
Pig是一个高级数据流语言,用于处理大规模数据集。它提供了一种类似于脚本的语言,使得用户可以轻松地编写数据处理程序,并运行在Hadoop集群上。
3. HBase
HBase是一个分布式、可扩展的NoSQL数据库,基于HDFS构建。它适用于存储非结构化或半结构化数据,并支持实时读取和写入操作。
4. Sqoop
Sqoop是一个数据迁移工具,用于在Hadoop和传统数据库之间传输数据。它支持多种数据源,如MySQL、Oracle等,使得用户可以轻松地将数据迁移到Hadoop生态系统。
5. Spark
Spark是一个快速、通用的大数据处理引擎,支持多种编程语言,如Scala、Python、Java等。它具有高吞吐量和低延迟的特点,适用于实时数据处理、机器学习等场景。
Hadoop生态系统为处理大规模数据集提供了丰富的组件和工具。通过深入了解这些组件,企业可以构建高效、可扩展的大数据处理平台,从而更好地应对大数据时代的挑战。
相关推荐

教程资讯
教程资讯排行