
hadoop系统架构,Hadoop系统架构详解
时间:2024-10-25 来源:网络 人气:
Hadoop系统架构详解
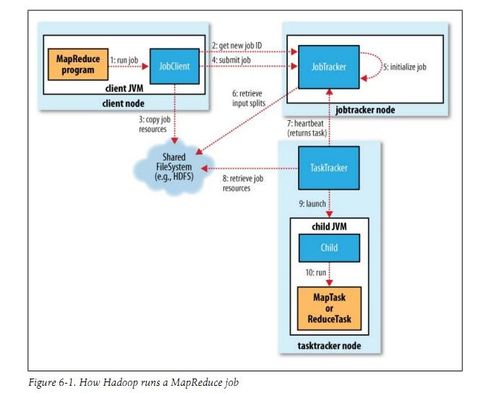
随着大数据时代的到来,Hadoop作为一款开源的大数据处理框架,已经成为业界处理海量数据的首选工具。本文将详细介绍Hadoop的系统架构,帮助读者更好地理解其工作原理。
一、Hadoop简介
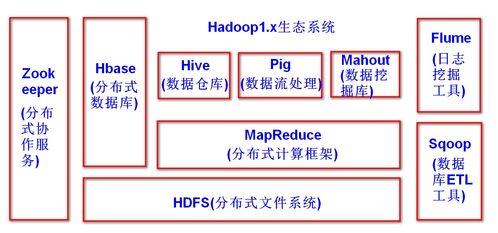
Hadoop是一个分布式计算框架,由Apache软件基金会开发。它主要用于处理大规模数据集,通过分布式存储和分布式计算来提高数据处理效率。Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。
二、Hadoop系统架构概述

Hadoop系统架构主要分为以下几个层次:
1. 应用层
应用层是Hadoop系统架构的最上层,包括各种基于Hadoop开发的应用程序。这些应用程序可以是对HDFS文件系统的操作,也可以是运行在MapReduce框架上的数据处理任务。
2. 作业层

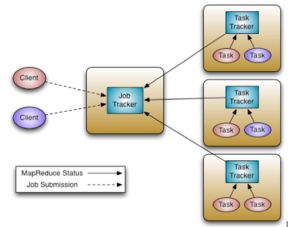
作业层负责将用户提交的任务分解成多个MapReduce作业,并管理这些作业的执行过程。作业层包括JobTracker和TaskTracker两个组件。
3. 资源管理层

资源管理层负责管理集群中的资源,包括计算资源(CPU、内存)和存储资源。Hadoop的资源管理层由YARN(Yet Another Resource Negotiator)实现。
4. 存储层
存储层是Hadoop系统架构的核心,负责存储和管理大规模数据集。HDFS是Hadoop的分布式文件系统,它将数据存储在多个节点上,并通过副本机制保证数据的可靠性和容错性。
5. 计算层

计算层负责执行数据处理任务,包括MapReduce和Tez等计算框架。MapReduce是Hadoop的核心计算框架,它将数据处理任务分解成Map和Reduce两个阶段,通过分布式计算提高数据处理效率。
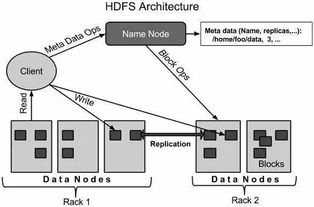
三、HDFS架构详解
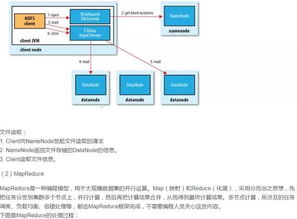
HDFS(Hadoop Distributed File System)是Hadoop的分布式文件系统,它采用主从架构,由一个NameNode和多个DataNode组成。
1. NameNode

NameNode是HDFS的主节点,负责管理文件系统的命名空间和客户端对文件的访问。NameNode维护一个文件系统的元数据,包括文件和目录的名称、权限、大小、块信息等。
2. DataNode

DataNode是HDFS的从节点,负责存储实际的数据块。每个DataNode都维护一个本地文件系统,并定期向NameNode汇报其存储的数据块信息。
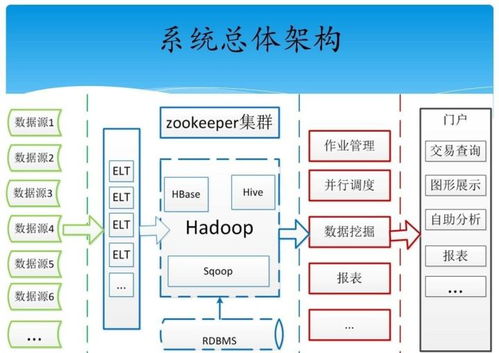
四、MapReduce架构详解
MapReduce是Hadoop的核心计算框架,它将数据处理任务分解成Map和Reduce两个阶段,通过分布式计算提高数据处理效率。
1. Map阶段

Map阶段负责将输入数据分解成键值对,并输出中间结果。Map任务通常由客户端程序执行,并将中间结果写入本地磁盘。
2. Shuffle阶段
Shuffle阶段负责将Map阶段的中间结果按照键进行排序和分组,以便Reduce阶段可以按照键进行聚合。
3. Reduce阶段
Reduce阶段负责对Shuffle阶段的输出结果进行聚合,生成最终的输出结果。Reduce任务通常由集群中的节点执行。
Hadoop系统架构通过分布式存储和分布式计算,为大规模数据处理提供了高效、可靠的解决方案。了解Hadoop的系统架构对于开发大数据应用具有重要意义。
相关推荐

教程资讯
教程资讯排行









