
hdfs文件系统,大数据时代的存储利器
时间:2024-11-03 来源:网络 人气:
HDFS文件系统:大数据时代的存储利器
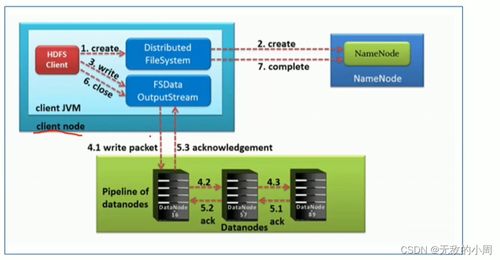
随着大数据时代的到来,数据量呈爆炸式增长,传统的文件存储系统已经无法满足海量数据的存储需求。HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)作为一种分布式文件系统,应运而生,成为了大数据存储的利器。
一、HDFS概述
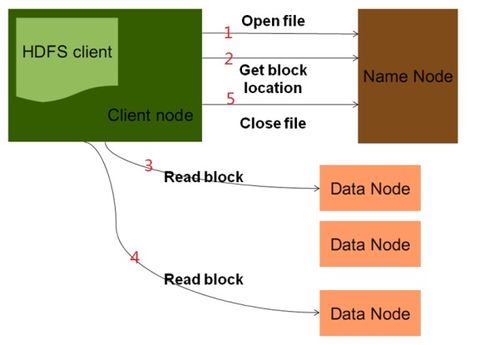
HDFS是Hadoop生态系统中的核心组件之一,它借鉴了Google的GFS(Google File System)的设计思想,具有高容错性和高可扩展性,能够在廉价硬件上存储海量数据。HDFS特别适合处理大规模数据集,广泛应用于大数据存储和分析场景中。
二、HDFS架构设计
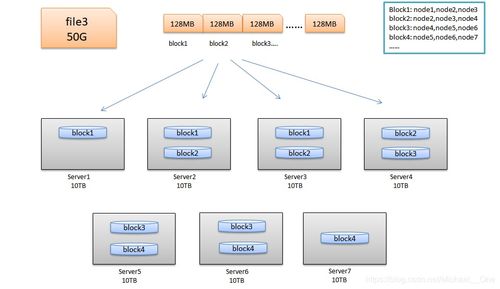
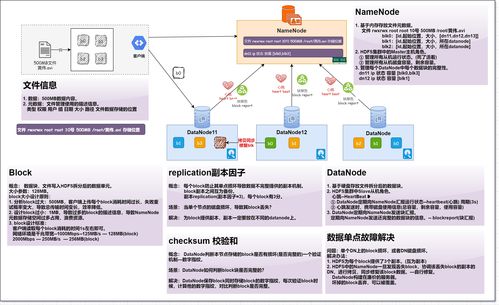
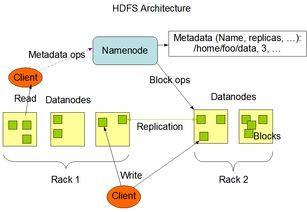
HDFS采用了主从架构模式,主要由以下几个核心组件构成:
NameNode:负责管理文件系统的元数据,包括文件目录结构、文件块位置信息等。
DataNode:负责实际的数据存储,每个文件被拆分成多个数据块存储在DataNode上。
Secondary NameNode:负责定期对NameNode的元数据进行快照,作为辅助节点,不是主备关系。
客户端(Client):客户端通过与NameNode和DataNode交互来读写数据。
三、NameNode详解
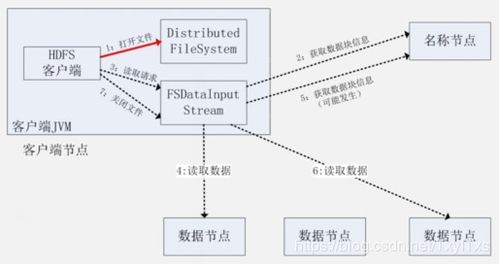
NameNode是HDFS的核心组件,负责管理整个文件系统的命名空间。其主要职责包括:
维护文件系统的目录结构
记录每个文件和文件块的位置
负责数据的复制管理和负载均衡
NameNode本身不存储实际的数据,而是存储文件系统的元数据,如文件目录结构、文件块位置信息等。
四、DataNode详解

DataNode负责实际的数据存储,每个文件被拆分成多个数据块存储在DataNode上。其主要职责包括:
存储实际的数据块
响应客户端的读写请求
定期向NameNode发送心跳信息,以保持集群的稳定性
五、HDFS的优势
HDFS具有以下优势:
高容错性:数据自动保存多个副本,提高容错性。某个副本丢失后,可以自动恢复。
高扩展性:当HDFS系统的存储空间不够时,只需添加一台新的机器到当前集群中即可完成扩容。
高吞吐量:HDFS采用主从架构,可以充分利用集群的计算资源,提高数据读写速度。
低成本:HDFS可以在廉价硬件上运行,降低大数据存储成本。
六、HDFS的应用场景
HDFS适用于以下场景:
大规模数据集存储
一次写入,多次读取的数据存储
需要高容错性和高扩展性的数据存储
HDFS作为一种分布式文件系统,在处理海量数据存储方面具有显著优势。随着大数据时代的到来,HDFS在各个领域得到了广泛应用,成为了大数据存储的利器。
相关推荐
教程资讯
教程资讯排行









