hadoop文件系统,什么是Hadoop分布式文件系统(HDFS)?
时间:2024-11-06 来源:网络 人气:
深入解析Hadoop分布式文件系统(HDFS)
什么是Hadoop分布式文件系统(HDFS)?
Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的一个核心组件,它是一个专为大规模数据存储而设计的分布式文件系统。HDFS的设计目标是提供高吞吐量的数据访问,适合于运行在低成本的硬件上,并且能够跨多个节点进行扩展。
HDFS的核心特性
高吞吐量:HDFS为大数据应用提供了高吞吐量的数据访问,适合于批处理作业。
高可靠性:HDFS通过数据冗余和错误恢复机制,确保了数据的高可靠性。
可扩展性:HDFS能够通过增加节点来水平扩展,以适应不断增长的数据量。
流式数据访问:HDFS支持流式数据访问,适合于大数据处理和分析。
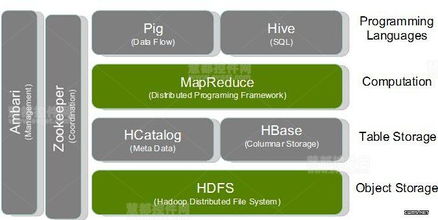
HDFS的架构
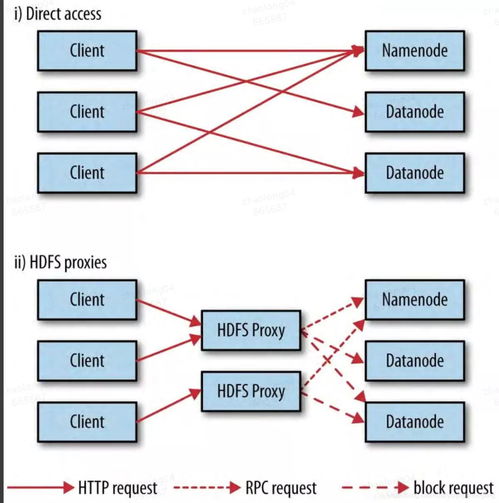
HDFS采用主/从(Master/Slave)架构,主要包含以下组件:
1. NameNode
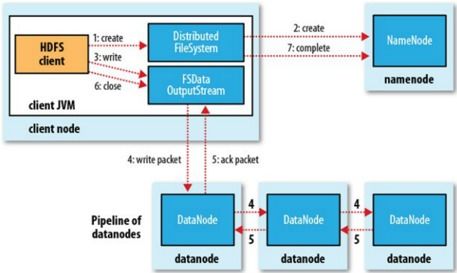
NameNode是HDFS的主节点,负责管理文件系统的命名空间和客户端对文件的访问。NameNode存储了文件系统的元数据,如文件名、目录结构、文件权限等。
2. DataNode
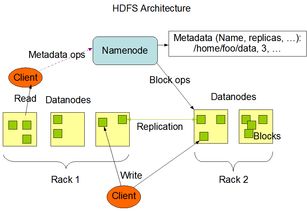
DataNode是HDFS的从节点,负责存储实际的数据块。每个DataNode负责存储一部分文件的数据块,并响应来自NameNode的读写请求。
3. Secondary NameNode
Secondary NameNode是NameNode的辅助节点,负责定期备份NameNode上的元数据,以防止数据丢失。Secondary NameNode不参与数据块的存储和读写操作。
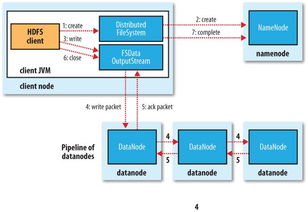
HDFS的数据存储机制
HDFS将数据存储在多个节点上,以实现高可靠性和可扩展性。以下是HDFS的数据存储机制:
1. 数据块
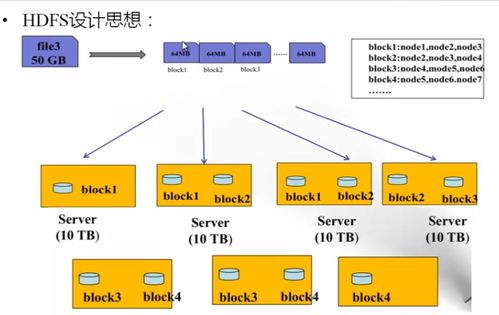
HDFS将数据分割成固定大小的数据块,默认大小为128MB或256MB。每个数据块存储在一个或多个DataNode上。
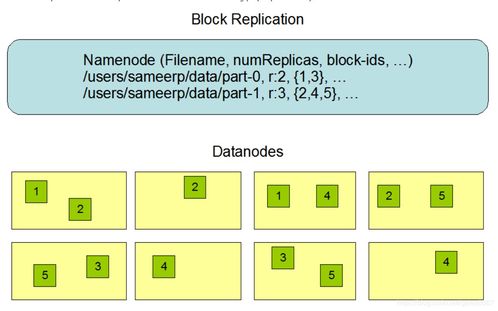
2. 数据复制

HDFS默认将每个数据块复制3份,分别存储在3个不同的节点上。这种数据复制机制提高了数据的可靠性,即使某个节点发生故障,数据也不会丢失。
3. 数据均衡

HDFS会定期检查数据块的分布情况,如果发现某个节点上的数据块过多,会将其复制到其他节点,以保持数据块的均匀分布。
HDFS的应用场景
HDFS适用于以下场景:
大规模数据存储:HDFS可以存储PB级别的数据,适合于大数据应用。
高吞吐量数据访问:HDFS为大数据应用提供了高吞吐量的数据访问,适合于批处理作业。
流式数据访问:HDFS支持流式数据访问,适合于实时数据处理和分析。
HDFS的优缺点
以下是HDFS的优缺点:
优点
高可靠性:HDFS通过数据冗余和错误恢复机制,确保了数据的高可靠性。
高吞吐量:HDFS为大数据应用提供了高吞吐量的数据访问,适合于批处理作业。
可扩展性:HDFS能够通过增加节点来水平扩展,以适应不断增长的数据量。
缺点
低延迟:HDFS不适合低延迟的应用,如在线事务处理。
不支持随机读写:HDFS不支持随机读写,适合于顺序读写。
Hadoop分布式文件系统(HDFS)是一个专为大规模数据存储而设计的分布式文件系统。它具有高可靠性、高吞吐量和可扩展性等特点,适用于大数据应用。然而,HDFS也存在一些缺点,如低延迟和支持随机读写等。在实际应用中,需要根据具体需求选择合适的文件系统。
相关推荐
教程资讯
教程资讯排行