hbase系统架构,HBase系统架构详解
时间:2024-11-06 来源:网络 人气:
HBase系统架构详解
HBase,作为Apache Hadoop生态系统中的一个重要组成部分,是一种分布式、可伸缩的NoSQL数据库,它基于Google的Bigtable模型设计,旨在处理大规模数据集。本文将详细介绍HBase的系统架构,帮助读者更好地理解其工作原理和设计理念。
一、HBase概述
HBase运行在Hadoop分布式文件系统(HDFS)之上,利用HDFS提供的高可靠性和高吞吐量特性。它支持海量数据的存储和快速随机访问,适用于需要实时读取和写入大量数据的场景。
二、HBase系统架构
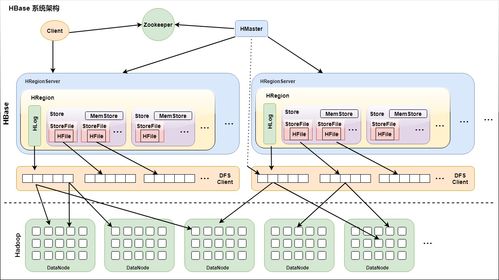
HBase的系统架构主要由以下几个核心组件构成:
1. 客户端(Client)
客户端负责与HBase集群进行交互,执行数据读写操作。客户端通过HBase API与HBase集群通信,包括HBase Shell、Java API、REST API等。
2. ZooKeeper
ZooKeeper是一个分布式协调服务,用于维护HBase集群的元数据信息,如集群状态、Region分配等。ZooKeeper还负责Master和RegionServer的选举,确保集群的稳定性和高可用性。
3. Master
Master是HBase集群的管理节点,负责集群的元数据管理、Region分配、负载均衡、集群维护等功能。Master节点负责监控集群状态,并在需要时重启RegionServer。
4. RegionServer
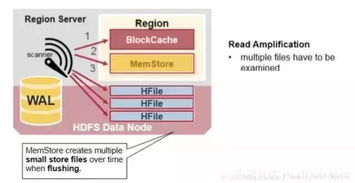
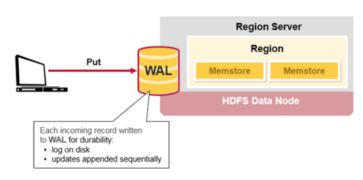
RegionServer是HBase集群中的工作节点,负责处理客户端的读写请求。每个RegionServer维护一组Region,Region是HBase数据的基本存储单元。RegionServer负责数据的读写、存储、压缩、清理等操作。
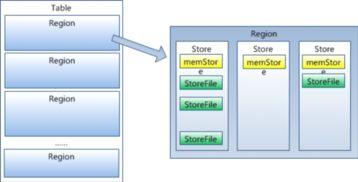
5. Region
Region是HBase数据的基本存储单元,由一个或多个Store组成。每个Region包含一个或多个列族,列族是一组具有相同数据类型的列的集合。RegionServer负责维护分配给自己的Region,并响应用户的读写请求。
6. Store
Store是Region的核心组件,负责存储Region中的数据。每个Store对应一个列族,包含一个MemStore和若干个StoreFile。MemStore是内存中的数据缓冲区,当MemStore达到一定大小后,会触发flush操作,将数据写入磁盘中的StoreFile。
三、HBase数据存储
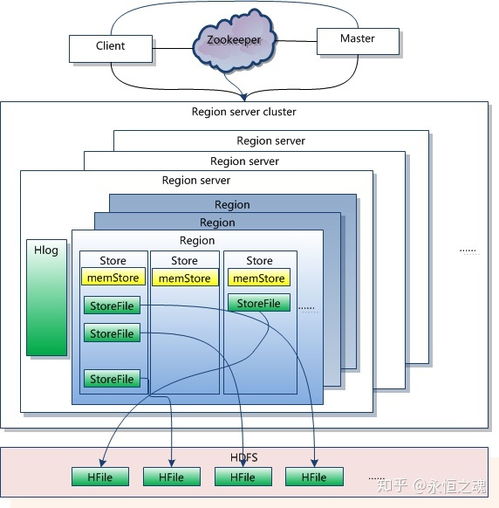
HBase采用列式存储方式,将数据按照列族进行组织。每个列族包含多个列,列可以进一步细分为列限定符。HBase的数据存储在HDFS上,以HFile格式存储。HFile是一种不可变的、顺序存储的文件格式,支持快速随机访问。
四、HBase优缺点
HBase具有以下优点:
高可靠性:HBase基于HDFS,具有高可靠性。
高吞吐量:HBase支持海量数据的存储和快速随机访问。
可伸缩性:HBase支持水平扩展,可以轻松应对数据量增长。
易于使用:HBase提供丰富的API和工具,方便用户进行数据操作。
然而,HBase也存在一些缺点:
不适合事务处理:HBase不支持事务,不适合需要强一致性保证的场景。
查询性能有限:HBase的查询性能受限于列式存储和HDFS的访问模式。
维护成本较高:HBase需要定期进行数据清理和压缩,维护成本较高。
HBase是一种高性能、可伸缩的分布式数据库,适用于处理大规模数据集。了解HBase的系统架构有助于更好地利用其特性,为实际应用提供有力支持。
相关推荐

教程资讯
教程资讯排行