
kafka系统架构,Kafka系统架构详解
时间:2024-11-06 来源:网络 人气:
Kafka系统架构详解

Apache Kafka是一种高吞吐量的分布式发布-订阅消息系统,它广泛用于构建实时数据流平台。本文将深入探讨Kafka的系统架构,包括其核心组件、工作原理以及如何实现高可用性和可扩展性。
一、Kafka的核心组件

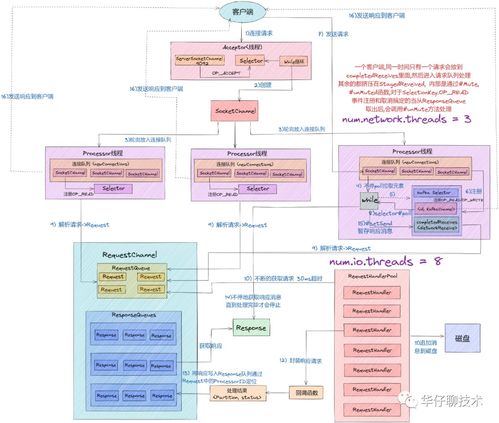
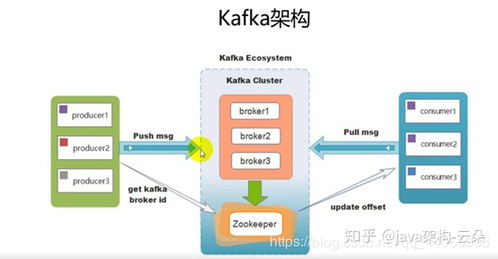
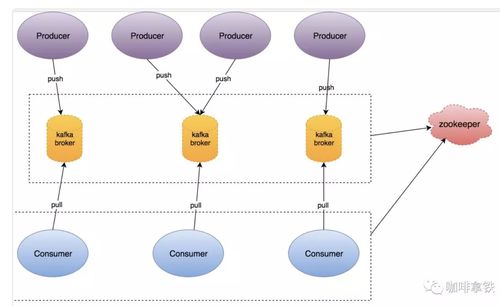
1. Broker:Kafka集群由多个Broker组成,每个Broker是一个服务节点,负责存储数据、处理客户端请求以及与其他Broker通信。

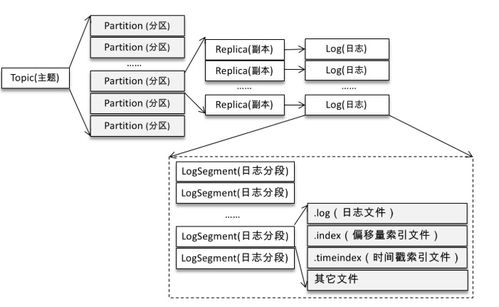
2. Topic:Topic是Kafka中的消息分类,类似于数据库中的表。每个Topic可以包含多个分区(Partition),分区是Kafka中数据存储的基本单位。

3. Partition:分区是物理上的存储单元,每个分区存储着消息的有序集合。分区内的消息是有序的,但不同分区之间的消息是无序的。
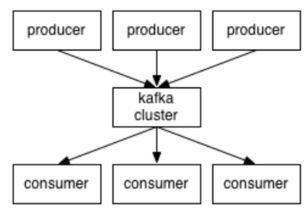
4. Producer:生产者是消息的发送者,负责将消息发送到Kafka集群中的指定Topic。
5. Consumer:消费者是消息的接收者,从Kafka集群中订阅并消费消息。

6. Consumer Group:消费者组是一组消费者,它们共同消费一个或多个Topic中的消息。消费者组内部的消息是负载均衡的,但组与组之间是隔离的。

7. Zookeeper:Zookeeper用于管理Kafka集群的元数据,如Broker的注册信息、Topic的元数据等。

二、Kafka的工作原理

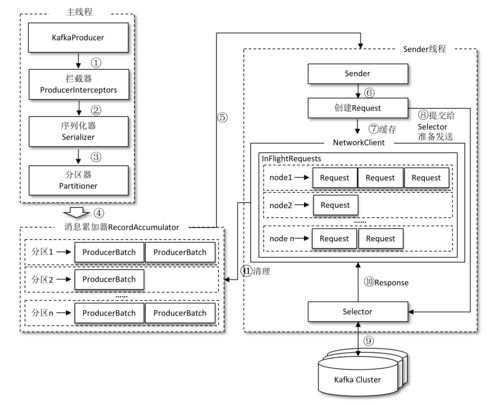
1. 消息生产:生产者将消息发送到指定的Topic,消息会被写入到对应的分区中。Kafka支持批量发送和压缩消息,以提高性能。
2. 消息存储:Kafka将消息持久化到磁盘,并使用日志结构存储(Log Structured Storage)来优化读写性能。

3. 消息消费:消费者从Kafka集群中订阅并消费消息。消费者可以指定从哪个偏移量开始消费,或者从最新消息开始消费。

4. 负载均衡:Kafka通过分区和副本机制来实现负载均衡和高可用性。每个分区可以有多个副本,副本分布在不同的Broker上。
三、Kafka的高可用性和可扩展性
1. 高可用性:Kafka通过副本机制来实现高可用性。每个分区有多个副本,主副本负责处理读写请求,其他副本作为备份。当主副本发生故障时,副本会自动进行选举,新的主副本接管服务。

2. 可扩展性:Kafka支持横向扩展,通过增加Broker节点来提高集群的吞吐量。Kafka的分区机制允许数据均匀地分布在多个节点上,从而提高系统的可扩展性。
四、Kafka的优缺点

1. 优点:
高吞吐量:Kafka能够处理高并发的消息传输。
高可靠性:Kafka通过副本机制和持久化存储来保证数据不丢失。
可扩展性:Kafka支持横向扩展,易于扩展集群规模。
实时处理:Kafka支持实时数据处理和分析。
2. 缺点:
复杂度:Kafka的配置和运维相对复杂。
单节点性能:单个Broker的性能可能受到磁盘I/O和CPU资源的限制。
Apache Kafka是一种高性能、可扩展、高可靠性的消息队列系统,适用于构建实时数据流平台。通过理解Kafka的系统架构和工作原理,开发者可以更好地利用Kafka的优势,构建高效、可靠的分布式系统。
作者 小编
相关推荐




教程资讯
教程资讯排行









