
linux系统故障排查,从基础到实战
时间:2024-11-09 来源:网络 人气:
Linux系统故障排查全攻略:从基础到实战
在Linux系统运维过程中,系统故障是不可避免的。快速准确地排查和解决故障,对于保障系统稳定运行至关重要。本文将详细介绍Linux系统故障排查的步骤、方法和常用工具,帮助运维人员高效处理各种系统问题。
一、故障排查的基本思路
1. 确定故障现象
故障现象是定位问题的前提。可以通过收集用户反馈、系统日志、监控报警信息等途径,准确了解故障表现,如系统无法访问、响应缓慢、服务中断等。
2. 定位故障范围
根据故障现象,初步判断故障范围可能涉及以下方面:
硬件问题:如磁盘损坏、内存故障、网卡故障等。
操作系统问题:如系统资源耗尽、内核崩溃、配置错误等。
应用层问题:如程序崩溃、死锁、数据库连接超时等。
网络问题:如网络中断、延迟过高、DNS解析失败等。
3. 收集故障信息
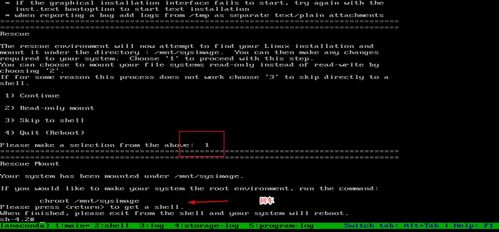
收集故障信息是解决问题的关键。以下方法可以帮助收集故障信息:
查看系统日志:系统日志是系统问题的第一手信息,可以从系统日志、应用日志、网络日志中查找故障线索。
Linux系统日志:
/var/log/messages
/var/log/syslog
4. 分析与诊断
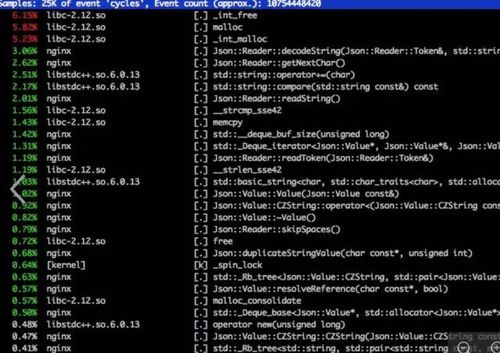
系统资源监控工具:如top、htop、nmon等。
网络故障排查工具:如ping、traceroute、mtr等。
日志分析工具:如logwatch、swatch等。
文件系统与磁盘排查工具:如fsck、e2fsck等。
5. 实施修复
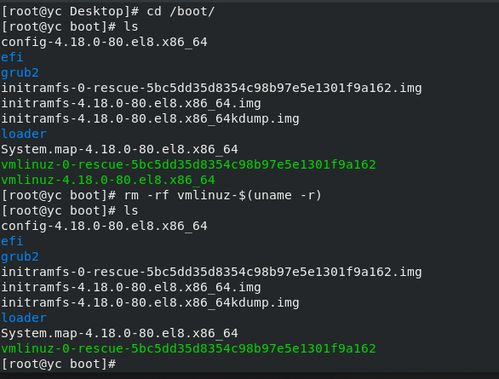
重启服务或系统。
修复损坏的文件系统。
调整系统参数或配置。
更新或修复软件包。
在解决问题后,记录故障原因、修复过程和经验教训,以便未来参考。
二、实战案例
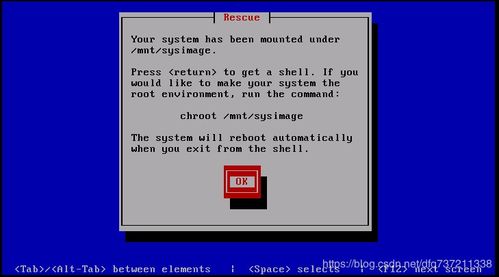
1. 服务器响应缓慢
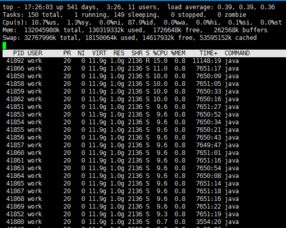
使用top或htop命令查看CPU和内存使用情况。
使用iostat命令查看磁盘I/O情况。
使用mtr命令检查网络延迟和丢包情况。
优化系统配置,如调整内核参数、调整进程优先级等。
2. 服务无法启动
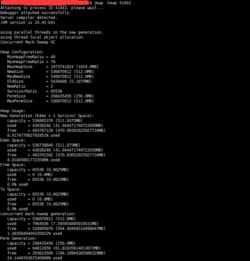
检查服务配置文件,确保配置正确。
检查服务依赖关系,确保所有依赖都已安装。
检查系统资源,如内存、磁盘空间等。
查看系统日志,查找错误信息。
3. 系统无法联网
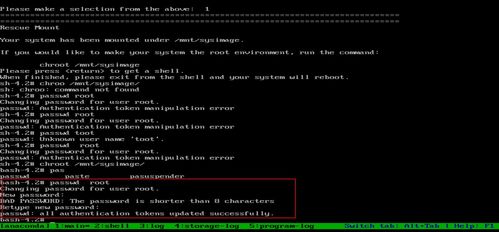
检查网络配置文件,确保配置正确。
使用ping命令测试网络连接。
检查DNS解析是否正常。
检查路由配置是否正确。
Linux系统故障排查
相关推荐




教程资讯
教程资讯排行

系统教程
- 1 安卓原生系统应用加密,技术原理与安全防护解析”
- 2 安卓手机安装系统语言,安卓手机系统语言安装与切换指南
- 3 skyui系统是安卓吗,SkyUI系统——基于安卓的蔚来手机专属操作系统”
- 4 安卓系统如何设置外放,轻松切换音频输出设备”
- 5 安卓系统碎片怎么处理,优化手机性能的实用技巧
- 6 升级安卓8.0系统失败,安卓8.0升级失败?揭秘常见原因及解决方案
- 7 安卓系统iso光盘镜像,安卓系统ISO光盘镜像生成与使用指南
- 8 鸿蒙系统平板安卓1.0,操作系统革新与用户体验对比
- 9 小米安卓6.0系统降级,安全、稳定回归旧版本体验”
- 10 迷你电脑安卓双系统,轻松实现Windows与安卓无缝切换








