
linux系统诊断,全面解析故障排查与解决策略
时间:2024-11-12 来源:网络 人气:
Linux系统诊断:全面解析故障排查与解决策略

在Linux系统运维过程中,系统故障是不可避免的。快速准确地诊断和解决故障对于保障系统的稳定性和运行至关重要。本文将全面解析Linux系统诊断的方法和策略,帮助运维人员提高故障排查效率。
一、故障排查的基本思路
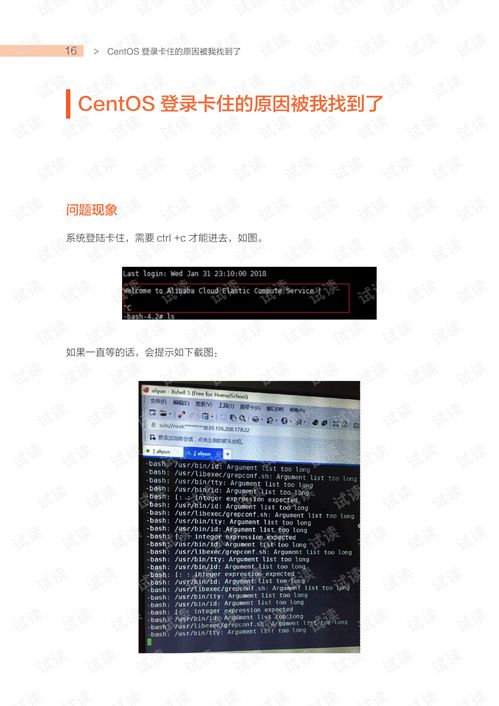
在进行Linux系统诊断时,可以遵循以下六步基本思路:
确定故障现象:首先明确故障的具体表现,如服务中断、系统响应缓慢等。
定位故障范围:根据故障现象,从硬件、操作系统、应用层和网络等方面缩小故障范围。
收集故障信息:收集系统日志、监控数据等,为后续分析提供依据。
分析与诊断:对收集到的信息进行分析,找出故障原因。
实施修复:根据分析结果,采取相应的修复措施。
二、实战案例:服务器响应缓慢
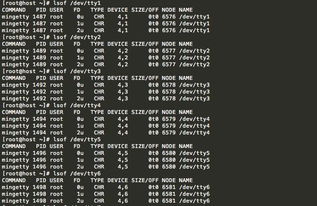
以下以服务器响应缓慢为例,展示故障排查的具体步骤:
确定故障现象:服务器响应缓慢,用户访问速度变慢。
定位故障范围:初步判断为CPU、内存、I/O或网络问题。
收集故障信息:使用top、vmstat、iostat等命令查看系统资源使用情况。
分析与诊断:通过分析命令输出,发现CPU使用率较高,内存使用率接近上限,I/O等待时间较长。
实施修复:根据分析结果,优化系统配置,调整进程优先级,增加内存等。
三、常用故障排查工具

系统资源监控工具:top、htop、nmon等。
网络故障排查工具:ifconfig、ping、traceroute、netstat等。
日志分析工具:logwatch、swatch、syslog等。
文件系统与磁盘排查工具:fsck、df、du等。
四、系统调优方法与技巧
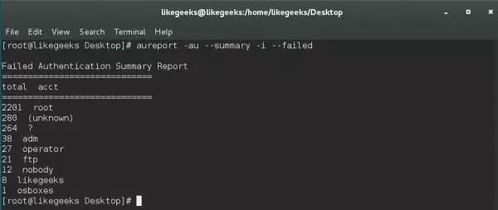
调整内核参数:修改文件描述符限制、优化网络栈参数等。
优化文件系统:选择适合的文件系统,定期进行磁盘碎片整理。
内存管理:配置swap空间、启用透明大页等。
调度进程:调整进程优先级、使用控制组限制资源使用。
提高安全性和稳定性:定期更新系统、实施最小权限原则。
使用监控工具进行诊断:安装Prometheus、Grafana等,分析日志文件。
Linux系统诊断是运维工作的核心技能,掌握故障排查思路、工具和方法对保障系统稳定运行非常重要。通过本文的介绍,希望读者能够更好地理解和应对Linux系统故障,提高运维效率。
相关推荐




教程资讯
教程资讯排行









