
hdfs系统,深入解析HDFS——分布式文件系统的基石
时间:2024-11-15 来源:网络 人气:
深入解析HDFS——分布式文件系统的基石

随着大数据时代的到来,数据量呈爆炸式增长,传统的文件存储系统已经无法满足海量数据存储和高效访问的需求。HDFS(Hadoop Distributed File System)作为一种分布式文件系统,应运而生,成为了大数据处理的基础设施。本文将深入解析HDFS的原理、架构和特性,帮助读者更好地理解这一分布式文件系统的基石。
一、HDFS的起源与发展
HDFS起源于Google的GFS(Google File System)论文,由Apache Hadoop项目组进行开源实现。HDFS的设计目标是提供高吞吐量的数据访问,适合大规模数据集的存储和处理。自2006年HDFS开源以来,它已经成为了大数据生态系统中的核心组件,被广泛应用于各种大数据应用场景。
二、HDFS的架构
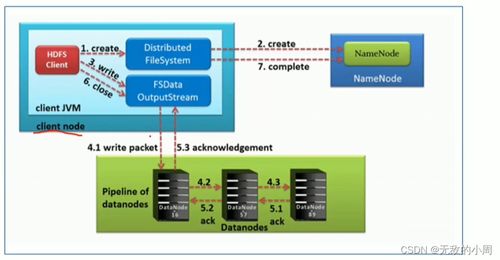
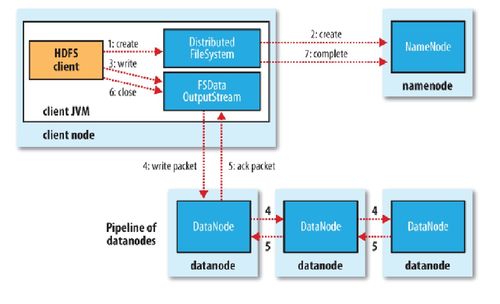
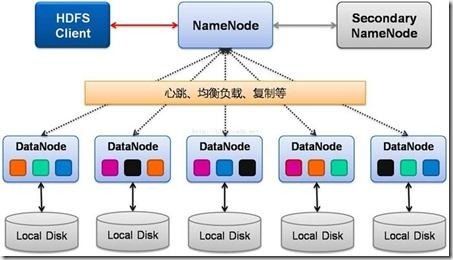
HDFS采用主从(Master-Slave)架构,主要由两个核心组件组成:NameNode和DataNode。
NameNode:作为HDFS的主节点,负责管理文件系统的命名空间、客户端的读写请求以及集群的元数据信息。NameNode维护一个全局的文件系统树,记录每个文件的存储位置、副本数量等信息。
DataNode:作为HDFS的工作节点,负责存储实际的数据块(Block)以及与NameNode的通信。DataNode将数据块存储在本地磁盘上,并响应NameNode的读写请求。
三、HDFS的数据存储与访问
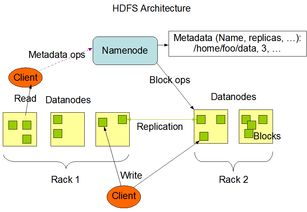
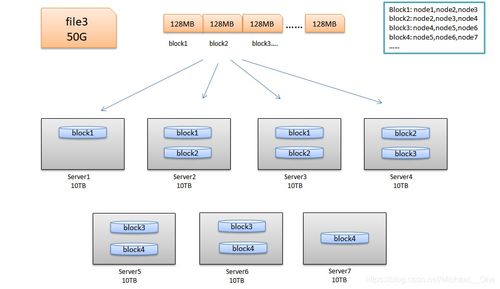
HDFS将数据存储在一系列的块(Block)中,每个块的大小默认为128MB或256MB。这些数据块被分散存储在多个DataNode上,以提高数据访问的效率和可靠性。
数据复制:HDFS采用数据复制机制,将每个数据块复制多个副本,存储在不同的DataNode上。默认情况下,HDFS会复制3个副本,以提高数据的可靠性和容错能力。
数据访问:客户端通过NameNode获取数据块的存储位置,然后直接与对应的DataNode进行通信,读取或写入数据。HDFS支持高吞吐量的数据访问,特别适合大数据处理场景。
四、HDFS的特性
HDFS具有以下特性,使其成为大数据处理的首选文件系统:
高可靠性:通过数据复制和故障检测机制,HDFS能够保证数据的可靠性,即使部分节点发生故障,也不会导致数据丢失。
高吞吐量:HDFS支持高吞吐量的数据访问,特别适合大规模数据集的处理。
可扩展性:HDFS可以轻松地扩展到数千个节点,以适应不断增长的数据量。
高容错性:HDFS能够自动检测和恢复节点故障,保证系统的稳定运行。
五、HDFS的应用场景
HDFS广泛应用于以下场景:
大数据存储:HDFS可以存储PB级别的数据,适合大规模数据集的存储。
大数据处理:HDFS可以作为Hadoop生态圈中的数据源,支持MapReduce、Spark等大数据处理框架。
数据仓库:HDFS可以作为数据仓库的基础设施,支持Hive、Impala等数据仓库工具。
HDFS作为一种分布式文件系统,为大数据处理提供了坚实的基础。其高可靠性、高吞吐量和可扩展性等特点,使其成为了大数据生态圈中的核心组件。随着大数据技术的不断发展,HDFS将继续发挥重要作用,推动大数据应用的普及和发展。
相关推荐

教程资讯
教程资讯排行









