
java爬虫系统,深入解析Java爬虫系统的设计与实现
时间:2024-11-24 来源:网络 人气:
深入解析Java爬虫系统的设计与实现
一、Java爬虫系统的概述
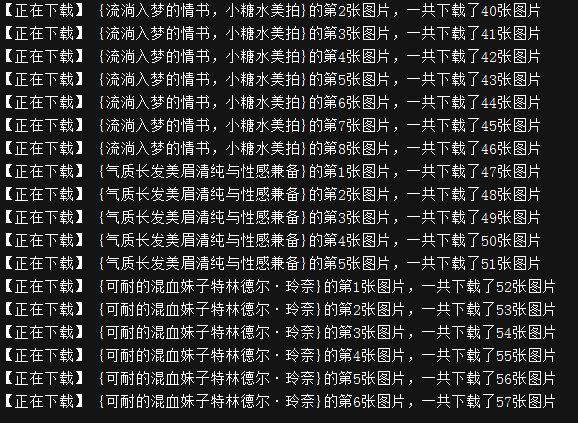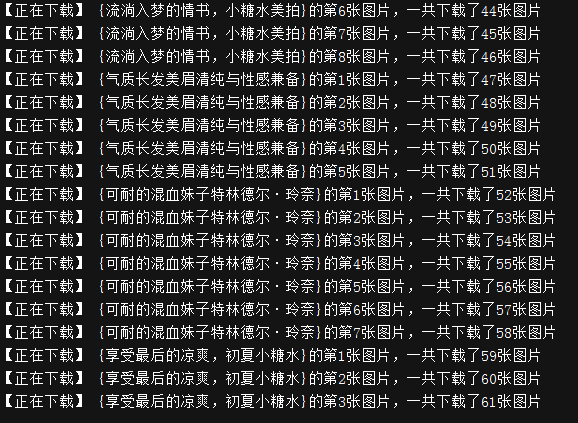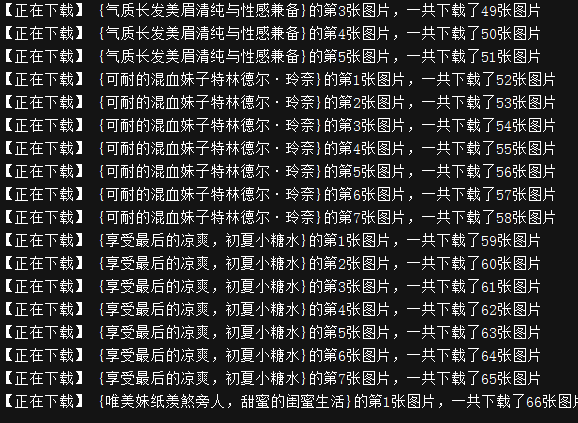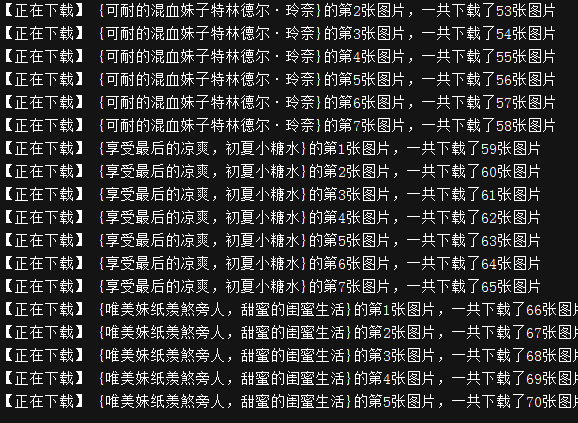
Java爬虫系统是一种利用Java语言编写的程序,用于从互联网上自动抓取和解析网页内容。它能够模拟浏览器行为,遵循网站的robots.txt协议,合法合规地获取数据。Java爬虫系统广泛应用于搜索引擎、数据挖掘、舆情分析等领域。
二、Java爬虫系统的架构设计
Java爬虫系统的架构设计主要包括以下几个部分:
数据采集层:负责从互联网上抓取网页内容,包括URL获取、网页下载、HTML解析等。
数据处理层:负责对采集到的数据进行清洗、去重、存储等操作。
数据存储层:负责将处理后的数据存储到数据库或其他存储系统中。
数据展示层:负责将存储的数据以可视化的形式展示给用户。
三、Java爬虫系统的关键技术

Java爬虫系统的关键技术主要包括以下几方面:
网络爬虫框架:如Jsoup、WebMagic、Apache Nutch等,用于简化爬虫开发过程。
HTML解析库:如Jsoup,用于解析HTML文档,提取所需数据。
数据库连接池:如HikariCP,用于提高数据库访问效率。
多线程技术:用于提高爬虫系统的并发处理能力。
分布式爬虫技术:如Apache ZooKeeper,用于实现分布式爬虫系统。
四、Java爬虫系统的实现步骤

Java爬虫系统的实现步骤如下:
需求分析:明确爬虫系统的目标、功能、性能等要求。
系统设计:根据需求分析,设计爬虫系统的架构、模块、接口等。
代码编写:使用Java语言和爬虫框架编写爬虫程序,实现数据采集、处理、存储等功能。
测试与优化:对爬虫系统进行功能测试、性能测试,并根据测试结果进行优化。
部署与维护:将爬虫系统部署到服务器,并进行日常维护和更新。
五、Java爬虫系统的应用场景
Java爬虫系统在以下场景中具有广泛的应用:
搜索引擎:如百度、谷歌等,通过爬虫系统获取互联网上的网页内容,构建索引库。
数据挖掘:从互联网上获取大量数据,进行数据分析和挖掘,为企业和研究机构提供决策支持。
舆情分析:实时监测网络舆情,为政府、企业等提供舆情分析报告。
电子商务:从竞争对手网站获取商品信息,进行价格比较和数据分析。
Java爬虫系统在互联网数据获取和分析领域具有重要作用。本文从Java爬虫系统的概述、架构设计、关键技术、实现步骤和应用场景等方面进行了深入解析,旨在帮助读者了解Java爬虫系统的原理和应用。随着技术的不断发展,Java爬虫系统将在更多领域发挥重要作用。
相关推荐


教程资讯
教程资讯排行









