
kafka 消息系统,kafka官网
时间:2024-11-24 来源:网络 人气:980
深入解析 Kafka 消息系统:架构、原理与应用
一、Kafka 消息系统的概述

Apache Kafka 是一个分布式流处理平台,由 LinkedIn 开发并开源。它是一个高吞吐量、可扩展、可持久化的消息队列系统,主要用于构建实时数据流应用和流数据管道。Kafka 通过发布/订阅模式,允许生产者向主题(Topic)发布消息,消费者从主题中订阅并消费消息。
二、Kafka 的核心架构

1. Broker:Kafka 服务器,负责消息的存储和转发。

2. Topic:消息类别,Kafka 按照主题来分类消息。

3. Partition:主题的分区,一个主题可以包含多个分区,消息保存在各个分区上。

4. Offset:消息在日志中的位置,可以理解是消息在分区上的偏移量,也是代表该消息的唯一序号。
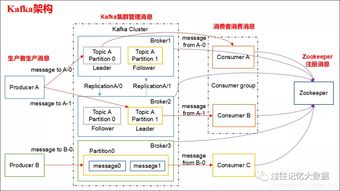
5. Producer:消息生产者,负责向 Kafka 发送消息。

6. Consumer:消息消费者,负责从 Kafka 消费消息。

7. Consumer Group:消费者分组,每个 Consumer 必须属于一个 group。

8. Zookeeper:保存着集群 broker、topic、partition 等元数据。

三、Kafka 的原理

1. 发布/订阅模式:生产者向 Kafka 发送消息时,会指定一个主题,Kafka 会将消息存储在对应主题的分区中。消费者订阅主题后,可以从分区中消费消息。

2. 分布式存储:Kafka 采用分布式存储方式,将消息存储在多个 Broker 上,提高系统的可用性和容错性。

3. 分区机制:Kafka 通过分区机制,将消息均匀地分布在多个 Broker 上,提高系统的吞吐量。

4. 副本机制:Kafka 为每个分区创建多个副本,提高系统的容错性。当某个 Broker 故障时,其他副本可以接管其工作。

5. 消息顺序性:Kafka 保证同一分区内消息的顺序性,确保消息的顺序消费。

四、Kafka 的应用场景

1. 实时数据流处理:Kafka 可以作为实时数据流处理平台,用于处理实时日志、实时监控、实时推荐等场景。

2. 消息队列:Kafka 可以作为消息队列,用于解耦系统组件,提高系统的可扩展性和可用性。

3. 数据集成:Kafka 可以作为数据集成平台,将不同来源的数据汇聚到一起,方便后续的数据分析和处理。

4. 事件源:Kafka 可以作为事件源,记录系统中的事件,方便后续的数据分析和处理。

五、Kafka 的优势

1. 高吞吐量:Kafka 具有高吞吐量,可以处理大量消息。

2. 可扩展性:Kafka 支持水平扩展,可以轻松地增加 Broker 数量,提高系统的吞吐量。

3. 容错性:Kafka 具有良好的容错性,可以保证系统的稳定运行。

4. 顺序性:Kafka 保证同一分区内消息的顺序性,确保消息的顺序消费。

5. 持久性:Kafka 将消息持久化到磁盘,保证数据的可靠性。

六、Kafka 的局限性

1. 单线程模型:Kafka 采用单线程模型,可能会影响系统的性能。

2. 分区数量限制:Kafka 对分区数量有一定的限制,可能会影响系统的可扩展性。

3. 数据存储格式:Kafka 使用二进制格式存储数据,可能会增加数据处理的难度。

Apache Kafka 是一个功能强大的分布式流处理平台,具有高吞吐量、可扩展性、容错性等优点。在实时数据流处理、消息队列、数据集成等领域,Kafka 都有广泛的应用。Kafka 也存在一些局限性,如单线程模型、分区数量限制等。在实际应用中,需要根据具体需求选择合适的消息队列系统。
作者 小编
相关推荐




教程资讯
教程资讯排行









