impala系统,高效的大数据查询引擎解析
时间:2024-11-26 来源:网络 人气:
Impala系统:高效的大数据查询引擎解析

随着大数据时代的到来,如何高效地处理和分析海量数据成为了企业关注的焦点。Impala作为一款高性能的大数据查询引擎,凭借其独特的优势,在众多大数据解决方案中脱颖而出。本文将深入解析Impala系统的特点、架构以及应用场景。
一、Impala系统简介

Impala是由Cloudera公司主导开发的一款开源大数据查询引擎,它基于Hadoop生态系统,能够对存储在HDFS、HBase和Kudu等存储系统中的PB级数据进行实时查询和分析。与传统的Hive系统相比,Impala具有更高的查询性能和更低的延迟,能够满足企业对实时数据查询的需求。
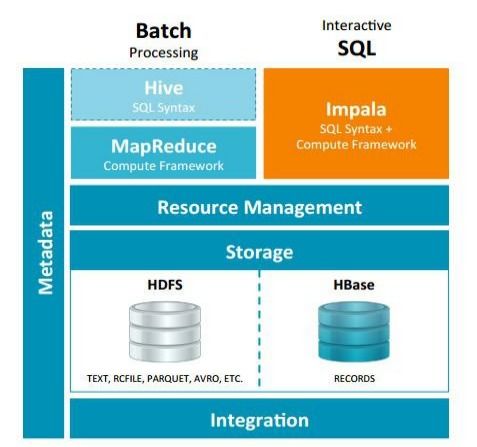
二、Impala系统架构

Impala系统主要由以下几个组件构成:
Impalad守护进程:负责执行查询任务,与客户端进行通信,并将查询任务分发到各个节点上并行执行。
Statestore存储状态:负责收集集群中各个节点的资源信息和健康状态,同步节点信息以及查询调度。
metadata元数据 / metastore元存储:存储可用于Impala数据的信息,包括可用数据库及其结构。
三、Impala系统特点
Impala系统具有以下特点:
高性能:基于内存计算,能够对PB级数据进行交互式实时查询/分析。
低延迟:无需转换为MR,直接读取HDFS数据,查询延迟低。
兼容性:兼容HiveSQL,支持JDBC/ODBC远程访问。
易用性:支持Data Local,一次性加载所有数据(元数据)。
安全性:支持SQL92标准,并具有丰富的权限管理功能。
四、Impala系统应用场景

Impala系统适用于以下场景:
实时数据查询:企业需要对实时数据进行查询和分析,如电商、金融等行业。
数据仓库:企业需要构建数据仓库,对历史数据进行查询和分析。
大数据分析:企业需要对海量数据进行挖掘和分析,如机器学习、数据挖掘等。
五、Impala系统与其他大数据查询引擎的比较

与Shark、Spark SQL、Drill等大数据查询引擎相比,Impala具有以下优势:
性能:Impala基于内存计算,查询性能更高。
兼容性:Impala兼容HiveSQL,易于迁移现有Hive应用。
易用性:Impala支持JDBC/ODBC远程访问,方便与其他系统集成。
Impala系统作为一款高效的大数据查询引擎,在实时数据查询、数据仓库和大数据分析等领域具有广泛的应用前景。随着大数据技术的不断发展,Impala系统将继续优化和完善,为企业提供更加优质的大数据解决方案。
相关推荐

教程资讯
教程资讯排行