
flume 系统日志,flume官网
时间:2024-12-01 来源:网络 人气:
Flume:高效的企业级系统日志收集解决方案
在当今大数据时代,企业级系统日志的收集、存储和分析变得尤为重要。Apache Flume作为一款开源的分布式日志收集系统,能够帮助企业高效地处理海量日志数据。本文将详细介绍Flume的特点、架构、配置以及在实际应用中的优势。
一、Flume概述

Apache Flume是一个分布式、可靠、高可用的海量日志收集系统。它可以将来自不同数据源(如文件、网络套接字、系统日志等)的日志数据收集起来,并传输到指定的目的地(如HDFS、HBase、Kafka等)。
二、Flume架构
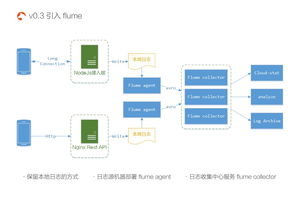
Flume的核心是Agent,它包含三个核心组件:Source、Channel和Sink。
Source:负责从数据源收集数据,并以Event(事件)的形式传递给Channel。
Channel:作为Source和Sink之间的桥梁,负责缓存Event,保证数据在收发时的一致性。
Sink:从Channel中消费数据(Event),并将其传输到指定的目的地。
三、Flume配置
Flume的配置文件以XML格式编写,主要包括以下内容:
Agent配置:定义Agent的名称、Source、Channel和Sink等组件。
Source配置:定义数据源类型、数据源路径、数据格式等。
Channel配置:定义Channel的类型、容量、事务管理等。
Sink配置:定义数据目的地类型、数据目的地路径等。
四、Flume优势
Flume在企业级系统日志收集方面具有以下优势:
分布式架构:支持分布式部署,能够处理海量日志数据。
高可靠性:采用事务机制,保证数据传输的可靠性。
灵活配置:支持多种数据源和目的地,满足不同场景的需求。
易于扩展:可根据实际需求添加自定义组件,提高系统性能。
五、Flume应用场景
Flume在企业级系统日志收集方面具有广泛的应用场景,以下列举几个典型应用:
日志收集:收集来自服务器、应用程序、网络设备等设备的日志数据。
数据聚合:将来自不同数据源的日志数据进行聚合,便于后续分析。
数据存储:将日志数据存储到HDFS、HBase、Kafka等大数据存储系统。
实时监控:实时监控系统日志,及时发现异常情况。
Apache Flume是一款高效的企业级系统日志收集解决方案,具有分布式、可靠、灵活等优势。在处理海量日志数据方面,Flume能够为企业提供强大的支持。随着大数据时代的到来,Flume在日志收集领域的应用将越来越广泛。
相关推荐
教程资讯
教程资讯排行









