基于dsp的语音识别系统设计
时间:2024-09-26 来源:网络 人气:
引言
随着科技的不断发展,语音识别技术已经广泛应用于各个领域,如智能家居、智能客服、语音助手等。DSP(数字信号处理器)因其强大的处理能力和低功耗特性,成为语音识别系统设计中的理想选择。本文将详细介绍基于DSP的语音识别系统设计,包括系统架构、硬件选型、软件实现等方面。
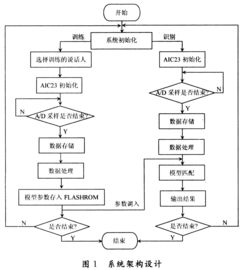
系统架构
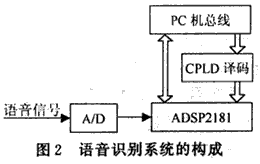
基于DSP的语音识别系统主要由以下几个部分组成:
麦克风阵列:用于采集语音信号。
A/D转换器:将模拟语音信号转换为数字信号。
DSP处理器:负责语音信号的预处理、特征提取、模式匹配等处理过程。
存储器:用于存储语音识别模型、参数等数据。
输出设备:如显示屏、扬声器等,用于展示识别结果。
硬件选型
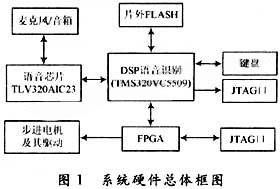
在选择硬件时,需要考虑以下因素:
处理能力:DSP处理器的处理能力应满足语音识别算法的计算需求。
功耗:低功耗设计有助于延长设备的使用寿命。
存储容量:足够的存储容量可以存储语音识别模型和参数。
接口:丰富的接口可以方便地与其他设备连接。
本文以TMS320C6713 DSP处理器为例,介绍硬件选型。
DSP处理器

TMS320C6713是一款高性能的DSP处理器,具有以下特点:
32位定点运算单元,支持浮点运算。
丰富的片上资源,如片上存储器、定时器、串行接口等。
低功耗设计,适用于便携式设备。
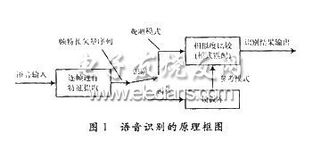
语音信号预处理
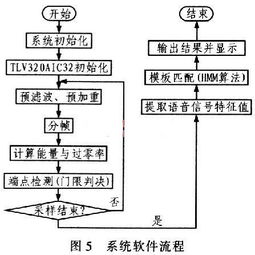
语音信号预处理是语音识别系统中的关键环节,主要包括以下步骤:
预滤波:去除噪声和干扰。
采样和量化:将模拟语音信号转换为数字信号。
加窗:减少边界效应。
端点检测:识别语音信号的起始和结束位置。
预加重:增强高频成分,提高语音识别性能。
特征提取
特征提取是语音识别系统中的核心环节,常用的特征提取方法有:
MFCC(梅尔频率倒谱系数):将语音信号转换为MFCC特征向量。
PLP(感知线性预测):提取语音信号的线性预测系数。
LPCC(线性预测倒谱系数):结合线性预测和倒谱系数的优点。
模式匹配
模式匹配是语音识别系统中的最后一步,常用的模式匹配方法有:
动态规划:计算未知语音信号与模型库中各个模型之间的相似度。
隐马尔可夫模型(HMM):根据HMM模型计算未知语音信号的概率。
神经网络:利用神经网络进行语音识别。
软件实现
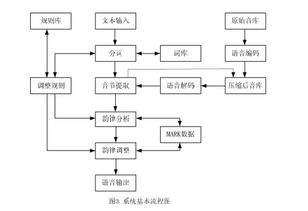
基于DSP的语音识别系统软件实现主要包括以下步骤:
编写语音信号预处理程序。
编写特征提取程序。
编写模式匹配程序。
编写用户界面程序。
基于DSP的语音识别系统具有高性能、低功耗、易于扩展等优点,在各个领域具有广泛的应用前景。本文详细介绍了基于DSP的语音识别系统设计,包括系统架构、硬件选型、软件实现等方面,为相关研究和开发提供了参考。
相关推荐

教程资讯
教程资讯排行